DITA Perspectives
DITA is not defined as a flat list of elements, but each element is either a base element or it derives as a specialized version of another element. This hierarchy should actually decrease the cognitive complexity of a vocabulary because it allows you to find an element faster than working with a flat list.
In this article, I want to show the hierarchy of elements in DITA and then explore how you can take advantage of this in understanding the DITA architecture, learning DITA, document authoring, etc.
All the scripts I used to generate these diagrams can be found in the DITA Perspectives Github Project.
Overview of DITA
DITA Shells
DITA 1.3 defines multiple types of documents. Along with the generic topic and map, there are
also many specialized topics types and maps types. Each type of document is defined by a
schema that is marked as a shell schema, a schema that should be an
entry point, the one that should be referred from an XML document. All the defined
shells are presented in the following diagram, grouped by the folder they are defined
in:

DITA Modules
class attribute
that encodes information about the type of that element, for
example:<step class="- topic/li task/step">A sequence of one or more tokens of the form"modulename/typename", with each token separated by one or more spaces, wheremodulenameis the short name of the vocabulary module andtypenameis the element type name. Tokens are ordered left to right from most general to most specialized.
By analyzing all the class values from all the elements defined in the schemas, I can identify
the base modules (top level ones). In this case, topic and a hierarchy
implied by how the elements are defined by this relation from more general to more
specialized modules, thus identifying how modules are specialized from others (in this
example, task is specialized from topic).
The base DITA modules:

The modules specialization hierarchy:

DITA Elements
The total number of DITA elements defined in the schemas and how they are split into base elements, specialized element, and a highlight of the duplicate elements, while having the same name but being defined on a different module can be observed here:

Elements Split by Map and Topic Base

Topic Elements
The element information is projected on the topic base module:

Map Elements
The element information is projected on the map base module:

bookmap
Defined in ../data/rng/bookmap/rng/bookmapMod.rng

learningSummary
Defined in ../data/rng/learning/rng/learningSummaryMod.rng

learningPlan
Defined in ../data/rng/learning/rng/learningPlanMod.rng

learningOverview
Defined in ../data/rng/learning/rng/learningOverviewMod.rng

learningContent
Defined in ../data/rng/learning/rng/learningContentMod.rng

learningObjectMap
Defined in ../data/rng/learning/rng/learningObjectMapMod.rng

learningBase
Defined in ../data/rng/learning/rng/learningBaseMod.rng

learningGroupMap
Defined in ../data/rng/learning/rng/learningGroupMapMod.rng

learningAssessment
Defined in ../data/rng/learning/rng/learningAssessmentMod.rng

troubleshooting
Defined in ../data/rng/technicalContent/rng/troubleshootingMod.rng

reference
Defined in ../data/rng/technicalContent/rng/referenceMod.rng

task
Defined in ../data/rng/technicalContent/rng/taskMod.rng

glossentry
Defined in ../data/rng/technicalContent/rng/glossentryMod.rng

glossgroup
Defined in ../data/rng/technicalContent/rng/glossgroupMod.rng

concept
Defined in ../data/rng/technicalContent/rng/conceptMod.rng

subjectScheme
Defined in ../data/rng/subjectScheme/rng/subjectSchemeMod.rng

DITA Domains
Some DITA elements are defined to be part of a domain that can be added on any DITA document type as a pluggable component. A domain defines a number of semantic elements that are derived from other elements, providing a specialization of the base elements but reflecting the semantics of a domain, such as programming, software, etc.
DITA Learning Interaction Base 2 Domain

DITA Learning Map Domain

DITA Learning Interaction Base Domain

DITA Learning Metadata Domain

DITA Learning Domain

DITA Learning 2 Domain

DITA Abbreviated Form Domain

DITA Markup Name Mention Next v Domain

DITA MathML Domain
Added locally
DITA SVG

DITA User ADD Domain

DITA Equation Domain

DITA Task Requirements Domain

DITA Programming Domain

DITA XML Construct Domain

DITA Glossary Reference Domain

DITA Software Domain

DITA Release Management Domain

DITA XNAL Domain

DITAVAL Reference Domain

DITA Delay Resolution Domain

DITA Indexing Domain

DITA Hazard Statement Domain

DITA Highlight Domain

DITA Map Group Domain

DITA Utilities Domain

DITA Subject Classification Domain

Taking Advantage of DITA Element Hierarchy
Elements in DITA are defined not as a flat list of elements, but instead as a hierarchy, similar to a type hierarchy, and elements are either base elements or they are derived from another element. If we look at the analogy with a type system, the base elements are similar to the primitive types and the other elements are equivalent to derived types.
This is realized using values specified in the class attribute. These values specify the category and the name of the current element and (if we talk about a derived element) also the name and category of its parent, as well as all the ancestors up to the base element.
@class value for the <lcPlanTitle>
element
is:class="- topic/fig learningBase/fig learningPlan/lcPlanTitle"<lcPlanTitle> from the
learningPlan category and this is derived from the
<fig> element from the learningBase
category, which in turn is defined from the <fig> element from
the topic category.We can take this information into account in some situations.
Element Selection During Editing
To take advantage of the fact that elements in DITA form a hierarchy, one possibility is
to follow this hierarchy when we present the user with the choice of an element to
insert, so instead of presenting a flat list of choices, we can organize the elements
according to the hierarchy defined by the @class attribute values and
thus, if the user selects an unordered list (<ul> element) to
insert (for example), we can further present all the elements specialized from the
<ul> element that are valid in that position in the document.
Of course, this makes sense if the user is browsing for an element to insert, and the
user already knows the element and types its name, then we can just filter that name and
eventually, if there are elements specializing the one identified by the entered string,
then we can show them further.
Another possibility is to present a drop-down for an element that has specialized elements, and those are valid at that location, and allow the user to move to a more specialized element by selecting it from that drop-down.
Automatic Markup Detection
If we first detect the base element and then determine if it is in fact a more specialized one, it may help because it reduces the number of choices.
Soft Generalization
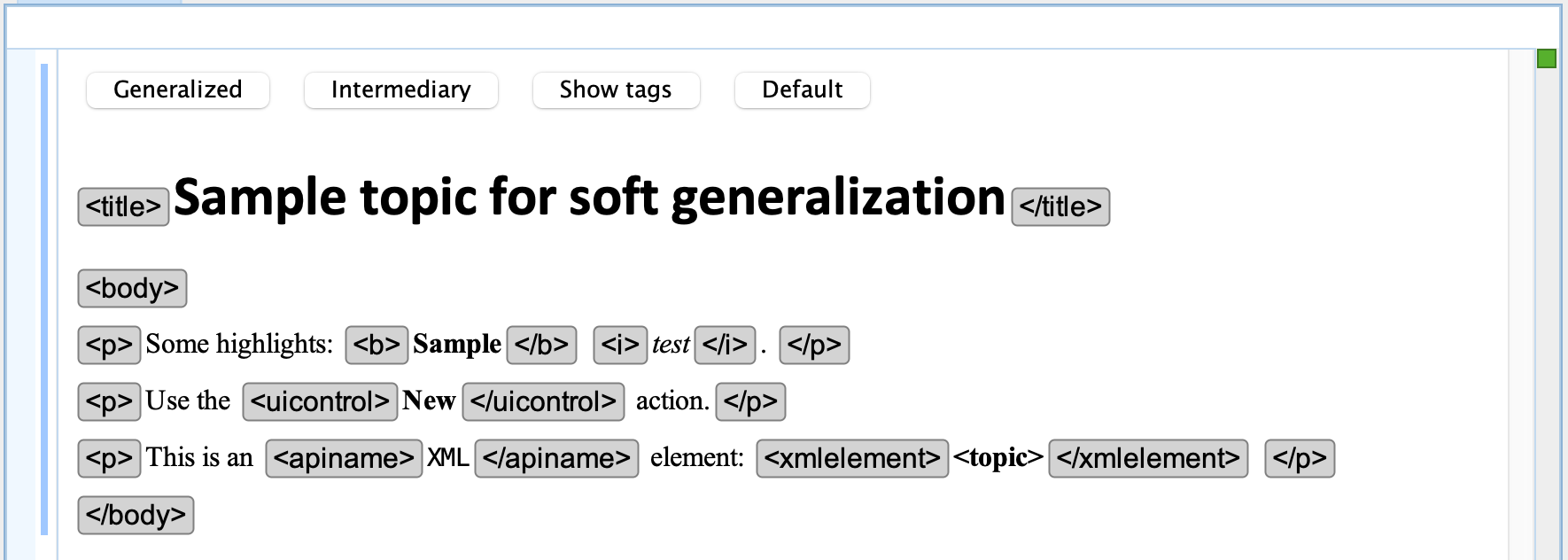
To visualize how a document will look like when it is generalized but without really generalizing it (that is without replacing the elements with more general ones), we implemented a CSS rendering to show the XML tags as if the document is generalized.
For example, an element on which we make the tags visible using CSS static content placed before and after the element looks like this:
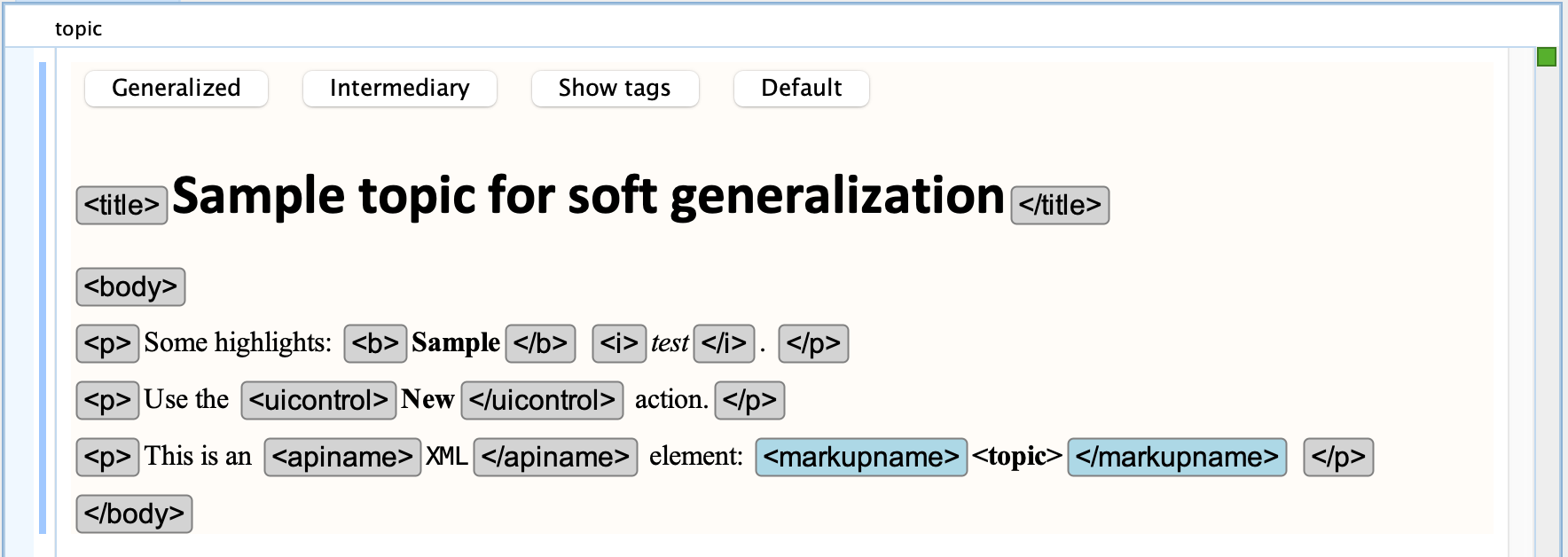
If we generalize on level, showing the first derived element type, then this sample
<xmlelement> will turn into
<markupname>:
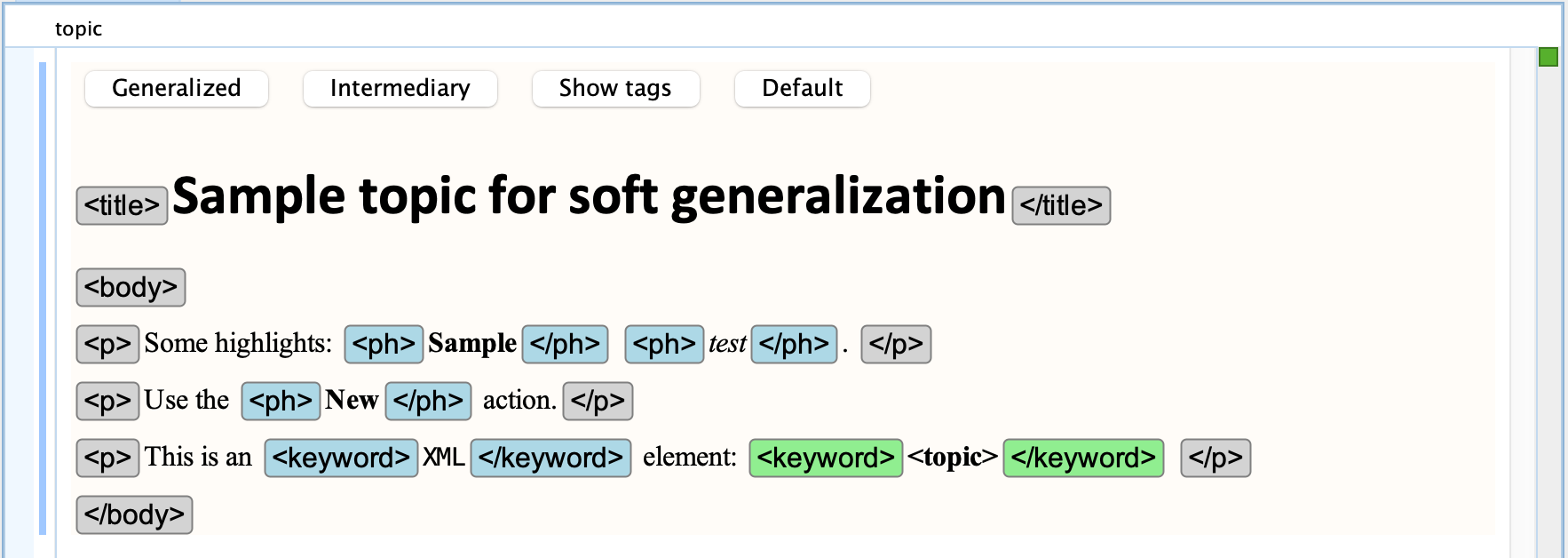
If we generalize to show the base elements, then many of the tag names will change, as highlighted in the following screen shot:
Exchanging DITA Documents
One advantage of using DITA is that we can tag at semantic level. For this to work, we need to create a specialization that exactly reflects the concepts the users of that specialization are familiar with. If one tries to layer its actual needs over an existing specialization (or one of the standard schemas), these may not exactly match the concepts of the audience and thus it will look like DITA is not the best fit.
However, the problem with a specialization is how do we exchange it with other parties? We need to also provide them with our specialization, and if they do not have our specialization, then what happens?
One approach is to export the DITA content as generalized content. Then import such a generalized package into an existing DITA installation by specializing as much as possible, taking into account what is available on the target DITA installation.
How can this be achieved?
From the class of the root element, we can identify the possible specialized root elements and check if we have them defined in a schema in the target DITA installation. Once we choose a root element, then we need to analyze the domain attributes of the root element and see what domains are defined in the target topic type and then specialize elements from those domains back. Otherwise, if a domain is not present in the target schema, we need to leave the base element.
We have support for generalization, which is relatively easy to implement, and we can probably also obtain the export package in a generalized form. However, we are missing a tool to take a generalized package, analyze a current DITA installation, and specialize everything so that it matches what is available in that specific DITA installation.